Searching, Thread-count and a Thanksgiving Miracle
Suppose that you have a collection of numbers or perhaps of WidgetManagerHandles -- could be most anything that can be sorted. We'll suppose that these are stored in an array and that you can take as much time as you need beforehand to organize the array, after which we will try to locate objects in it many times. The question is: What is the minimum number of item-to-item comparisons (on average) that is needed to locate a given item?
One obvious solution is to place the items in sorted order, then use binary search. This will find the item in log2(N) (where N is the number of items). Now I'll prove that this is the best possible solution. Consider: the array must be of at least length N to store the items. That means there are N possible locations. Each comparison gives us one bit of information (x < y is either True or False) -- by the pigeonhole principle it requires at least log2(N) bits to fully specify N possible results. Q.E.D.
It's a nice proof -- but it's wrong. To explain why, I'm going to detour a bit to discuss fabrics.
Suppose that you are a manufacturer of cloth -- or better yet, a
manufacturer of clothing who purchases a lot of cloth. You need to be
able to very accurately count the number of threads per inch (per
centimeter if you live anywhere other than the USA), and preferably do
so quickly and easily.  There exists a very clever solution
by name of the "Lunometer".
This is a strip of hard plastic etched with carefully drawn finely
spaced lines that vary in spacing along the length of the strip. Set it
on the cloth and look through -- at the one location where the spacing
of the lines matches the spacing of the threads in the cloth, you will
see a moiré
pattern, thus
allowing incredibly precise measurement of the thread count. It's a very
clever trick, and the device can still be purchased from the company
named for its inventor: Hans Peter Luhn.
There exists a very clever solution
by name of the "Lunometer".
This is a strip of hard plastic etched with carefully drawn finely
spaced lines that vary in spacing along the length of the strip. Set it
on the cloth and look through -- at the one location where the spacing
of the lines matches the spacing of the threads in the cloth, you will
see a moiré
pattern, thus
allowing incredibly precise measurement of the thread count. It's a very
clever trick, and the device can still be purchased from the company
named for its inventor: Hans Peter Luhn.
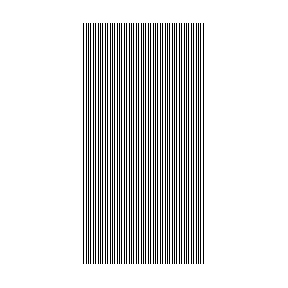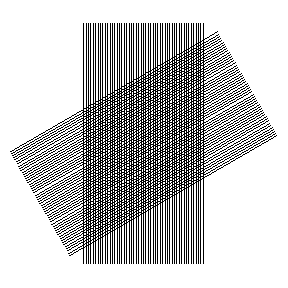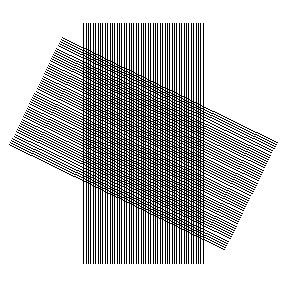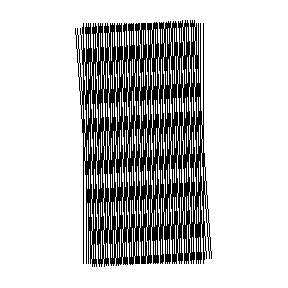{kind=link}
It was this clever trick (and other work in Textiles) which brought H. P. Luhn (born 1896 in Germany) to the USA. He later worked for IBM where he devised clever tricks to enhance the power of the punchcard and eventually became a pioneer in "information science" (that's what librarians study) -- discovering, among other things, that if you want to search a full-text index of a bunch of documents, the common words are useless (they occur everywhere) and the very rare words are too likely to be missing from any given document -- the usefulness of a keyword peaks somewhere in between.
But in between (in 1953), he was the first to publish about a clever trick which beats my log2(N) solution above. (At least, Knuth says he was the first. I'd look up the details in my office copy of Knuth except that I don't have an office copy of Knuth -- but numerous sources say he credits Luhn with being the first to publish about the technique, and Knuth is rarely wrong. Several others used the technique within the same decade -- probably some of them discovered it independently.)
Luhn's solution is called a "hash table". The fallacy in the proof above was the bit where I implicitly assumed that the comparisons were the only way to obtain information about the position in the array. In fact, hashing requires (approximately) ZERO comparisons! The trick is to use the item itself to directly determine the location in the array. If the item is an integer just use its value; if it is a WidgetManagerHandle then you need some way of generating an integer from it. A combination of using an array that's a bit bigger than N, and running the number through a fairly well-distributed function ("random function") before taking mod(array-length) and using it as an index will reduce the likelihood of two objects occupying the same location, and if it does "collide" then several clever techniques exist to handle it with a minimum of comparisons. The average number of comparisons required can easily be kept at 1 or 2... regardless of the size of N.
And this is why the hash table has always been my favorite data structure. I am just not clever enough -- if H. P. Luhn and others had not pointed it out to me I would continue to believe the "proof" I presented at the top of this essay. If you think about it, it is really quite astonishing that it should be possible to perform a lookup in some large group of objects taking constant time -- with absolutely NO dependence on the size of the group. So today for Thanksgiving, I would like to give thanks for Hans Peter Luhn and his most clever trick.

Posted Thu 22 November 2007 by mcherm in Programming